
佰维存储推出新一代高效能LPDDR5X内存,加速高性能终端设备AI应用
根据IDC预测,到2024年底,全球内置GenAI功能的智能手机出货量将达2.342亿部,同比增长363.6%,占整体出货量的19%;到2028年,这一数字预计将增长至9.12亿部,2024年至2028年的年复合增长率将达到78.4%。这种快速增长反映了市场对智能化服务和用户体验升级的强烈需求。GenAI功能不仅提供更个性化和智能的服务,还对智能手机硬件提出了更高要求,包括高算力SoC和高速可靠的嵌入式存储器,以确保手机流畅运行。 近日,佰维存储推出了新一代高效能内存——LPDDR5X,产品采用了1bnm制程工艺,与上一代产品相比,数据传输速率提高33%至8533Mbps,功耗降低25%,容量为8GB、12GB、16GB(ES阶段),为旗舰智能手机等终端设备提供卓越的性能与节能优势。 速率提升33%,加速高性能移动设备AI应用 佰维LPDDR5X的数据传输速率高达8533Mbps,较上代产品提升33%。这一提升主要得益于LPDDR5X采用了更先进的时钟技术和电路设计,支持更高的时钟频率,从而实现更快的数据传输。同时,为了在更高的频率下保持信号的稳定性和可靠性,LPDDR5X引入了更先进的信号完整性和抗干扰技术。 此外,LPDDR5X通过降低电压摆幅和采用更高效的驱动器和接收器设计,提高了信号的驱动能力和接收灵敏度,从而支持更高的数据传输速率。LPDDR5X还优化了内部时序参数,降低了CAS Latency,减少了数据访问等待时间,并通过改进行激活时间和行预充电时间,提高了整体效率,确保在高频率下仍能保持稳定和高效的数据传输,助力高性能移动设备AI应用。 功耗降低25%,更高能效提升设备续航能力 佰维LPDDR5X采用了先进的1bnm制程工艺和创新的电路设计。产品通过降低辅助电源电压(VDD2),减少了整体功耗。产品还进一步优化了动态电压和频率调节技术(DVFS),可根据实际负载情况动态调整工作电压和频率,在低负载时降低电压和频率,从而显著减少功耗;在空闲时进入深度睡眠模式(Deep-sleep mode),大幅降低功耗,延长电池寿命。 此外,LPDDR5X引入了自适应刷新技术,可根据实际工作条件动态调整刷新周期。这使得内存可以在保持数据完整性的同时,减少不必要的刷新操作,从而降低功耗。这些技术改进共同确保了LPDDR5X在高性能移动设备和计算平台中的高效能和长续航能力。 先进测试能力加持,打造高品质与一致性 DRAM芯片产品的核心技术之一在于测试。佰维存储基于对半导体存储器的全维度深入理解,采用了行业领先的半导体测试机台Advantest T5503HS2,并结合自研的自动化测试设备,以及自研测试软件平台、核心测试算法,覆盖了从设计验证到量产测试的全过程。通过先进的测试技术和严格的品质控制流程,佰维存储能够有效识别和排除潜在的质量问题,确保每一颗LPDDR5X芯片在性能、可靠性和稳定性方面均符合严苛标准,打造产品的高品质和一致性。 佰维存储LPDDR5X内存凭借其显著提升的数据传输速率和更低的功耗,可为高端智能手机、笔记本电脑、5G设备等高性能设备提供卓越的操作体验,并助力其实现更长的电池续航和更高的整体性能。展望未来,随着端侧AI应用的不断普及和发展,本地实现流畅运行大模型对终端设备的存储能力带来更高要求,驱动存储提速、扩容。佰维存储将继续发挥其研发封测一体化布局优势,通过在存储芯片设计、解决方案研发、封测制造等领域的持续研发投入和技术创新,不断满足智能终端市场对更高性能、更低功耗、更高可靠性的存储解决方案的需求,助力客户提升产品竞争力。
存储
BIWIN佰维 . 2024-11-12 1 2 1100

瑞萨推出全新RA8入门级MCU产品群,提供极具性价比的高性能Arm Cortex-M85处理器
全球半导体解决方案供应商瑞萨电子(TSE:6723)宣布,推出RA8E1和RA8E2微控制器(MCU)产品群,进一步扩展其业界卓越和广受欢迎的MCU系列。2023年推出的RA8系列MCU是首批采用Arm® Cortex®-M85处理器的MCU,实现市场领先的6.39 CoreMark/MHz(注)性能。新款RA8E1和RA8E2 MCU在保持同等性能的同时,通过精简功能集降低成本,成为工业和家居自动化、办公设备、医疗保健和消费品等大批量应用的理想之选。 RA8E1和RA8E2 MCU采用Arm Helium™技术,即Arm的M-Profile矢量扩展,与基于Arm Cortex-M7处理器的MCU相比,在数字信号处理器(DSP)和机器学习(ML)应用层面实现高达4倍的性能提升,使得快速增长的AIoT领域应用成为可能——在这一领域,高性能对于AI模型的执行至关重要。 RA8系列产品集成低功耗特性和多种低功耗模式,在提供业界卓越性能的同时,可进一步提高能效。低功耗模式、独立电源域、更低的电压范围、快速唤醒时间,以及较低的典型工作和待机电流组合,使得系统整体功耗更低。帮助客户降低整体系统功耗并满足相关法规要求。新款Arm Cortex-M85内核还能以更低的功耗执行各种DSP/ML任务。 RA8系列MCU由瑞萨灵活配置软件包(FSP)提供支持。FSP带来所需的所有基础架构软件,包括多个RTOS、BSP、外设驱动程序、中间件、连接、网络和TrustZone支持,以及用于构建复杂AI、电机控制和云解决方案的参考软件,从而加快应用开发速度。它允许客户将自己的既有代码和所选的RTOS与FSP集成,为应用开发打造充分的灵活性。借助FSP,可轻松将现有设计迁移至新的RA8系列产品。 Daryl Khoo, Vice President of Embedded Processing 1st Business Division at Renesas表示:“我们的客户对RA8 MCU的卓越性能赞不绝口,现在他们期望获得性能更高且功能更优化的版本,以满足其成本敏感的工业、视觉AI和中端图形应用需求。RA8E1和RA8E2为这些市场打造了性能和功能的完美平衡,并且借助FSP实现了在RA8系列内部或从RA6 MCU的轻松迁移。” RA8E1 MCU的关键特性 - 内核:360MHz Arm Cortex-M85,包含Helium和TrustZone技术 - 存储:集成1MB闪存、544KB SRAM(包括带ECC的32KB TCM、带奇偶校验保护的512KB用户SRAM)、1KB待机SRAM、32KB I/D缓存 - 外设:以太网、XSPI(八线SPI)、SPI、I2C、USBFS、CAN-FD、SSI、12位ADC、12位DAC、HSCOMP、温度传感器、8位CEU、GPT、LP-GPT、WDT、RTC - 封装:100/144引脚LQFP RA8E2 MCU的关键特性 - 内核:480MHz Arm Cortex-M85,包含Helium和TrustZone技术 - 存储:集成1MB闪存、672KB SRAM(包括带ECC的32KB TCM、带奇偶校验保护的512KB用户SRAM+额外128KB用户SRAM)、1KB待机SRAM、32KB I/D缓存 - 外设:16位外部存储器接口、XSPI(八线SPI)、SPI、I2C、USBFS、CAN-FD、SSI、12位ADC、12位DAC、HSCOMP、温度传感器、GLCDC、2DRW、GPT、LP-GPT、WDT、RTC - 封装:224引脚BGA 成功产品组合 瑞萨将全新RA8E1和RA8E2产品群MCU与其产品组合中的众多兼容器件相结合,创建了广泛的“成功产品组合”,包括入门级语音和视觉人工智能系统以及家用电器人机界面(HMI)。这些“成功产品组合”基于相互兼容且可无缝协作的产品,具备经技术验证的系统架构,带来优化的低风险设计,以加快产品上市速度。瑞萨现已基于其产品阵容中的各类产品,推出超过400款“成功产品组合”,使客户能够加速设计过程,更快地将产品推向市场。 关于瑞萨成功产品组合的更多信息您可识别下方二维码或复制链接至浏览器中打开查看: https://www.renesas.cn/zh/applications 关于入门级语音和视觉人工智能系统的更多信息您可识别下方二维码或复制链接至浏览器中打开查看: https://www.renesas.cn/zh/applications/industrial/building-automation/entry-level-voice-vision-ai-system 关于家用电器人机界面(HMI)的更多信息您可识别下方二维码或复制链接至浏览器中打开查https://www.renesas.cn/zh/applications/industrial/appliances/human-machine-interface-hmi-appliances 供货信息 RA8E1和RA8E2产品群MCU以及FSP软件现已上市。瑞萨还推出了RA8E1快速原型开发板,并计划于2025年第一季度初发布包括TFT显示屏在内的RA8E2评估套件。客户可以在瑞萨网站或通过分销商订购样品及套件。 关于RA8E1的更多信息您可识别下方二维码或复制链接至浏览器中打开查看: https://www.renesas.cn/zh/products/microcontrollers-microprocessors/ra-cortex-m-mcus/ra8e1-360mhz-arm-cortex-m85-based-entry-line-microcontroller-helium-and-trustzone 关于RA8E2的更多信息您可识别下方二维码或复制链接至浏览器中打开查看: https://www.renesas.cn/zh/products/microcontrollers-microprocessors/ra-cortex-m-mcus/ra8e2-480mhz-arm-cortex-m85-based-entry-line-graphics-microcontroller-helium-and-trustzone (注)EEMBC的CoreMark®基准测试用于衡量嵌入式系统中采用的MCU和CPU性能。 (备注)Arm和Arm Cortex是Arm Limited在欧盟和其它国家/地区的注册商标。本新闻稿中提及的所有产品或服务名称均为其各自所有者的商标或注册商标。
瑞萨电子
瑞萨电子 . 2024-11-12 1 1190

6位/24位,多通道,小封装,低功耗Δ-Σ型ADC--LTD2X20
LTD2X20是一款16(LTD2120)/24位(LTD2220),多通道,小封装,低功耗的Δ-Σ型ADC芯片。器件在连续模数转换下,所需要的工作电流最低仅为120μA,最高支持2k SPS的转换速率,提供最大128倍片上增益,且支持50&60Hz工频陷波。器件的功能模块还包括:低温漂高精度片上基准、两个高匹配度的激励电流源、高精度时钟、低边切换开关以及一个高精度温度传感器。使用LTD2X20可以极大的降低系统方案成本,达到单芯片实现系统级高精度测试的目的。 LTD2X20产品特性 低功耗:在Duty-cycle模式下低至120 μA 宽供电范围:2.3 V ~ 5.5 V 可编程增益:1 ~ 128倍 数据转换速率:最大2k SPS 有效分辨率:16位(LTD2120)/20位(LTD2220) 单周期稳定模式20 SPS速率下50 Hz & 60 Hz同步工频陷波 两路差分或4路单端输入 两路低失配可编程电流源:50 μA ~ 1.5 mA 片上2.048 V基准:温漂仅5 ppm/℃(typ.) 片上高精度时钟:误差1% 片上温度传感器:误差1℃ SPI兼容接口 小封装:4 mm * 4 mm VQFN-16L LTD2X20典型应用 温度传感器测量: 热敏电阻 热电偶 电阻式温度检测器(RTD):2线、3线或4线制类型 电阻桥式传感器测量: 压力传感器 应力计 衡器 便携式仪表 工厂自动化和过程控制温度与压力测量 LTD2X20功能模块图 LTD2X20产品优势 高集成度 低功耗 内置精密基准 LTD2X20产品订购信息
先积集成
先积集成 . 2024-11-12 1160

瑞萨与尼得科携手开发EV驱动电机系统的“8合1”概念验证方案
2024 年 11 月 11 日,中国北京讯 - 全球半导体解决方案供应商瑞萨电子(TSE:6723)今日宣布,率先在全球范围内推出用于电动汽车(EV)驱动电机系统(E-Axle)的“8合1”概念验证(注)(PoC)方案——通过单个微控制器(MCU)即可控制八项功能。该PoC与尼得科(Nidec)合作开发,集成电机、齿轮(减速机)、逆变器、DC/DC转换器和车载电池充电器(OBC)。此外,系统级测试也已顺利完成,以确保其性能。瑞萨将在2024年11月12日至15日德国慕尼黑电子展(B4展厅,179展台)现场展示全新8合1 E-Axle设计。 E-Axle作为电动汽车中的一个单元,集驱动电机、齿轮和逆变器于一体。通过整合多项功能,E-Axle系统能够减小系统尺寸和重量,简化电动车设计。瑞萨为开发这款全新的8合1E-Axle系统提供包括半导体和参考设计在内的关键组件。瑞萨同时计划基于该款PoC的参考设计,为各种“多合1”系统带来一站式半导体芯片及解决方案。借助这些解决方案,开发人员可以立即实施并评估“多合1”系统,从而加快电动汽车的开发。 除尼得科的电机和齿轮外,该PoC中的功能还包括瑞萨的逆变器(输出功率70至100kW,最高效率可达99%或更高)、1.5kWDC/DC转换器、6.6kW OBC、配电单元(PDU)、电池管理系统(BMS)以及汽车正温共效率(PTC)加热控制器。一般来说,E-Axle的每种功能都需要一个专用的MCU和电源管理IC(PMIC),以实现对“多合1”系统的控制。而瑞萨成功研发出的这一新型E-Axle系统仅需一个MCU和一个PMIC即可控制整个8合1系统。通过系统集成将这些功能集成到单个MCU,此款PoC可显著缩减元器件数量、系统成本及尺寸。 全新PoC经过最佳性能测试,包括众多瑞萨产品:车规级32位MCU RH850/U2B、用于MCU供电的PMIC、隔离栅极驱动器RAJ2930004AGM、用于逆变器的IGBT模块、针对OBC和DC/DC转换器的功率器件。得益于这些创新技术,瑞萨可为客户提供全面的系统与软件支持,以及“多合1”解决方案的关键元器件。瑞萨致力于打造包括参考设计和软件在内的全面系统解决方案,以加速电动车的开发。 Chris Allexandre, Senior Vice President and General Manager of Power at Renesas表示:“我们很荣幸与尼得科携手,共同推出创新的8合1 E-Axle解决方案,并已成功验证其卓越性能。我们承诺将提供丰富的功率半导体器件,并与瑞萨的数字产品结合,以完整的即用型系统级解决方案加速客户产品开发,缩短上市时间。” Ryuji Omura, Senior Vice President, Deputy Chief Technology Officer and Head of Nidec Semiconductor Solutions Center at Nidec表示:“在瞬息万变的电动汽车市场,对更小体积、更低成本E-Axle系统的需求与日俱增。使用单个ECU管理电动汽车动力总成控制单元将有助于降低系统的重量和成本,减少组件的数量。我们最先成功研发出这种创新的通过单个MCU控制8合1系统的PoC。在此,特别感谢瑞萨团队在这个项目中展现出的热情与卓越的合作精神。此外,由于不同细分市场多合1系统的集成水平各不相同,这个项目也让我们认识到开发可扩展设计方法的重要性。通过修改多核MCU的软件配置,我们期望为能够灵活适应各种组合的多合1平台奠定基础。”
驱动电机
瑞萨 . 2024-11-11 1 1290

泰矽微重磅发布超高集成度车规触控芯片TCAE10
智能按键和智能表面作为汽车智能化的重要部分,目前正处于快速发展阶段,电容式触摸按键凭借其操作便利性与小体积的优势,在汽车内饰表面的应用越来越广泛。对于空调控制面板、档位控制器、座椅扶手、门饰板、车顶控制器等多路开关的智能表面需要使用到较多的MCU管脚与片内资源,泰矽微TCAE12系列芯片可以很好地满足此类应用的需求。 此外,还存在另一大类应用如阅读灯、车窗控制按键、门把手、脚踢等需要使用少量按键,但在体积与成本等方面要求较高,市场需要更优化的方案以满足对成本与体积的要求。 泰矽微的TCAE10x系列(以下简称TCAE10)就是针对于成本和空间要求更高的需求所开发的一款高集成度、低成本、小体积的自容式混合信号触摸芯片。TCAE10除秉承TCAE12系列触控芯片所具有的功能集成和优越性能外,还进一步集成LIN收发器与高压电源供电,并集成硬件防水模拟模块,大幅提升防水效果,降低整体功耗,以及进一步提升了触控信噪比和稳定性。 TCAE10是目前全球唯一一款可同时实现超高集成度和超高触控性能的车规触控单芯片解决方案。TCAE10实现了对国外芯片的全面超越,宣告了泰矽微在全球车规触控芯片领域的绝对领导地位! 产品特色 工作电压5.5V~18V,支持40V抛负载电压 低功耗深度睡眠功耗50uA,支持LIN唤醒 集成高压LDO ARM Cortex M0 内核,48MHz 高频时钟,64 KB带ECC Flash和4 KB SRAM 集成5个通道的自容电容检测,电容充放电频率可调并支持调频模式 支持模拟方式屏蔽电极功能 9路GPIO,其中5个通道支持ADC输入,包括一对差分输入通道 14 位SAR ADC,500K SPS用于快速电容采样 支持失调电压补偿的PGA,1x-16x可调增益 支持SPI和UART串口 4路16 bit PWM 集成LIN收发器物理层 数据链路层符合LIN2.x和J2602标准 LIN接口支持115Kbps高速模式和20Kbps常规模式的切换 内部集成温度传感器,室温精度范围±3°C 独立的SWD高速烧写接口,用于产线的快速烧录,大幅提高生产效率 供电管脚VS符合ISO7637 和ISO16750浪涌、瞬态电压标准 封装DFN16 3mm*4mm AEC-Q100 Grade 1,Tj=-40°C~150 °C 芯片内部框图 图 1 系统框架图 产品优势 极简的的外围器件节省整体BOM成本 产品设计阶段充分考虑EMC要求,只需很少外围器件即可满足汽车EMC要求。 全国产化产业链单晶片设计提升性价比和可靠性 TCAE10采用了领先的全国产化产业链混合信号单晶圆工艺,将高压模拟、嵌入式存储以及其它模拟与数字外设集成于单一晶片,同时对芯片功能和性能的极致优化,在成本、性能等方面取得更好的平衡。 高性能自容式电容检测 TCAE10的应用框图如图2所示,模拟方式屏蔽电极功能提供良好的防水性能,Shield通道工作时,跟随检测通道的的波形如图3和图4所示 基于电荷平衡原理的电容检测方式提供高信噪比和抗干扰性能,SNR信噪比波形如图5 可调电容检测充放电时间和频率 自定义充放电次数和频率平衡性能和功耗 调频模式改善对外辐射 模拟开关模式充放电降低充放电时电压上升和下降沿,降低对外辐射 成熟的基线跟踪算法应对复杂的外部环境变化 图 2 TCAE10 典型应用 图 3 1次检测周期的(CH1-黄色屏蔽电极波形, CH2-绿色触摸电极波形) 图 4 1次充放电的Shield波形(CH1-黄色触摸电极波形, CH2-绿色屏蔽电极波形) 图 5 SNR高信噪比 低功耗 得益于TCAE10的单晶片设计,内部单元之间的功耗模式可以灵活配置以满足各种应用场景对功耗模式的要求。 典型应用场景,支持LIN唤醒模式下,芯片待机功耗可以实现小于50uA的指标,可以轻松满足几乎所有车厂对零部件功耗的要求,并给外围辅助电路留出足够的功耗裕量。 高生产效率 独立的SWD调试和烧录接口,满足产线快速程序烧录和调试的需求。 良好的LIN兼容性 TCAE10 LIN收发器和数据链路层基于泰矽微成熟的LIN 收发器IP设计,可以很好满足LIN2.X和SAEJ2602:2021等最新的LIN兼容性要求。 优异的EMC特性 TCAE10从芯片设计阶段就重点考虑了EMC问题,在电源管理、LDO等电路设计中增加了必要的防护措施,提高了PSRR性能,使得TCAE10方案可轻松通过ISO7637、ISO16750、ISO11452、CISPR25、SAEJ2962-1等相关EMC标准的测试。 高工作环境温度 TCAE10支持最高150℃工作环境温度,有效满足小体积、高亮度阅读灯等高温应用场景的需求。 典型应用场景 包括阅读灯、门把手、尾门脚踢、方向盘离手检测、车窗升降开关等(图6-图9)。 图 6 1路或2路阅读灯 图 7 门把手(单开关或双开关) 图 8 尾门脚踢检测 图 9 方向盘离手检测(单区,2区或3区模式,可选的屏蔽电极) 生态,工具和技术支持 为了便于用户快速进行方案的评估,助力项目快速落地,泰矽微提供TCAE10的EVK开发板供用户使用,并提供完整的SDK开发包,具体可通过sales@tinychip.com.cn咨询。 图 10 生态工具包
MCU
泰矽微 . 2024-11-11 1 860

IC 品牌故事 | 从收音机里诞生的电子厂,被动器件之王村田成长史
Murata是Murata Manufacturing Co., Ltd.的简称,中文名叫株式会社村田制作所,又称村田,成立于1950年12月23日(创业于1944年10月),总部在日本京都府长冈京市东神足1丁目10番1号。村田2023年度(截至2024年3月31日)营收为16,402亿日元(约107.4亿美元),营业利润率为13.1%。其主要产品包括电容器、电感器、EMI滤波器、表面波滤波器、高频模块、树脂多层基板、传感器等。 村田在国内的代理商有中电港、新蕾、北高智等。 村田的创始人是村田昭,1944年时他在京都市中心开设了一家150平方米的小工厂,开始生产氧化钛陶瓷电容,主要应用于外差式收音机。1950年12月正式改名为株式会社村田制作所,如今其陶瓷电容产品(MLCC)出货量高居首位,应用在了智能手机、平板电脑等多种电子设备中。当然,除了MLCC外,其电感器、EMI滤波器、高频通信、传感器等产品做得也不错。接下来请跟随芯查查一起探究一下村田的成长史吧! 图片来源:村田官网 初创阶段 故事要从1944年说起。 那一年,创始人村田昭在京都四条大宫北的旧染布厂挂上了“村田制作所”的招牌成为了一名个体户,开始了创业之路。 在二战后的混乱时期,收音机成为了重要的娱乐和信息来源,加上当时无线电广播开始面向民间播放,促使了收音机等设备的普及,电子元器件的需求迅速扩大。 当时的流行的超级外差法收音机普及最广,村田制作的温度补偿用电容器采用了氧化钛作为介质,广泛应用在了该收音机当中。 图:村田的温度补偿用电容器(来源:村田) 1950年村田重组为“株式会社村田制作所”,然而之后经历了大萧条下的经营危机,村田昭强烈感觉到,公司要成长发展下去,需要树立经营理念,因此,在1954年,他制定了起步的经营理念,以重整公司。 在接下来的几十年里,村田经历了两个主要的发展阶段,第一阶段从1944年——2005年, 主要专注于元器件产品的生产和销售 。这一时期,村田通过在欧美、东南亚、中国等地设立子公司和工厂,以及海外办事处等方式进行全球化扩张。 第二阶段从2006年开始,村田进行了多次大规模的海外并购,横向扩展业务范围,涉足 无线射频、电池电源、传感器等 多个领域。近年来,村田还积极布局汽车电子、物联网等新兴业务板块,实现多元化发展。 强化技术,积极投资研发 为了应对全球技术革新的浪潮,村田昭认为需要强化作为基础的技术力,于是在1955年将公司内的研究开发部门独立出来设立了“大宫技研”。并且,次年更名为“村田技术研究所”,搬迁至乙训郡长冈町。 研究所具备了以当时的企业规模来说比较先进的设备。 村田技术研究所向研究开发发起挑战,孕育出“果断投资研究开发”这一经营哲学,并成为之后村田在研究开发方面的思维基础。 1955年,晶体管收音机闪亮登场。可以说小型化、轻便化这一概念那时就开始形成。 村田使用作为压电材料具有划时代特性的锆钛酸铅,推出了AM收音机用陶瓷滤波器 。不过该产品的普及还需要再等10年。 1960年代后半期,村田开始开发“多层陶瓷电容器”。 从陶瓷材料、电极材料到制造设备,全部自主开发,并实施了合理化及进行改善,促成了如今独石陶瓷电容器的发展。 1970年,迎来了真正的电子设备时代,同年,村田同时在东证、大证的市场1部上市。 为了确立针对电子元件需求扩大的ASEAN市场的供应体制,1972年在新加坡设立了Murata Electronics Singapore(Pte.) LTD.,开始了陶瓷电容器的当地生产。 这是村田最初的海外当地生产公司,是朝着跨国企业进军的第一步。 另外,在日本国内,为了应对需求的多样化,相继新设了工厂和研究开发基地等,比如: 1983年,设立株式会社出云村田制作所,强化国内生产体制; 1987年,在滋贺县野洲市开设野洲事业所; 1988年在神奈川县横滨市绿区开设横滨开发中心,强化研究开发体制; 1988年,在泰国设立生产、销售公司Murata Electronics (Thailand), Lyd.,扩大全球性生产销售体制。 1989年,与电气音响株式会社合并,通过不断设立新的工厂、研发中心和办事处来进行扩张,规模开始越变越大。 到了1991年,迎来了70岁生日的村田昭卸任社长一职,村田泰隆接任。也是在这一年,村田顽童开始开发。 1992年,村田在中国北京设立办事处;1993年在马来西亚设立生产公司;1994年在中国无锡设立生产公司。 进入21世纪后,为了推动进一步发展,村田认为需要在之前的基础上培养指向客户及现场的经营文化,因此在2004年开始实施组织文化改革。 这一措施基于经营理念,从对社会的贡献、提高客户满意度(CS)、员工的工作价值与成长(ES)、事业战略等所有角度重新审视,构筑面向下个成长战略的体制。 并且,同年将总公司迁至JR长冈京站东侧,将总公司的功能和事业部的企划功能等关键功能集中起来。 此外,2007年村田泰隆社长就任代表董事会长,村田恒夫成为继任社长。 并购,开始多领域布局 2006年开始,村田进行了多次大规模海外并购,进行横向业务扩张,先后进入了无线射频、电源电池、传感器、通信模块、功率半导体和材料等业务领域,由原来的单一元器件产品线,转变为元器件和模块产品齐头并进的模式。 2006年村田收美国德州的SyChip公司,进入无线射频领域,共同开发蓝牙模块、GPS模块、WiFi、WiMax模块等产品; 2007年收购C&D科技的电源电子事业部,加强布局电源模组; 2012年以约1.95亿欧元收购芬兰MEMS传感器企业VTI,扩大传感器业务;同年,收购瑞萨功率放大器业务,与自有滤波器技术结合,提供高集成的模块;还收购了RF Monolithics Inc,发展通信模块和高频部件业务; 2013年收购晶振企业东京电波(Tokyo Denpa); 2014年收购Fabless射频IC制造商Peregrine半导体公司,巩固无线射频业务; 2016年收购塑料生产商Primatec,核心优势为液晶聚合物电子材料(LCP)技术;同年,收购索尼的锂电池业务; 2017年收购意大利RFID初创企业IDSolutions,涉足物联网;同年,并购美国初创企业Arctic Sand Technologies,布局功率半导体。 2021年收购美国Eta Wireless公司,获得智能手机节能技术; 2022年收购射频滤波器初创公司Resonant,获得XBAR滤波器解决方案,增强了其在无线射频领域的竞争力。 结语 自创立以来,村田始终在电子元器件领域深耕,通过不断对陶瓷特性的挖掘,获得了一系列技术性革新,拓展出了种类丰富的产品群。如今,村田已经形成了以电子陶瓷技术为核心,能够满足市场多种需求的产品阵容,奠定了其在陶瓷电容、射频、滤波器等电子元器件领域的头部企业地位。 Tips 截至发稿前,芯查查已收录村田物料数据、应用方案,datasheet,国内外及同品牌替代料等信息。
被动器件
芯查查资讯 . 2024-11-11 3 15 9736

边缘AI | 适用于MCU的NPU IP有哪些?
重点内容速览: | Arm Ethos NPU:已推出第三代,有20家合作伙伴 | 安谋科技:周易NPU系列 | Ceva:可提供一整套边缘AI处理器解决方案 | Cadence:Tensilica Neo NPU IP | 芯原:采用其NPU IP的AI类芯片出货量超过1亿颗 | Synopsys:ARC NPX6 NPU IP 系列 | 英业达:为低性能MCU量身定制的NPU 云端AI发展如火如荼的时候,边缘AI的发展也开始步入快车道,边缘AI芯片的需求日益增长。边缘AI芯片不仅需要具备低功耗、高性能、安全可靠的特性,同时还需要易于集成和部署。 而将AI加速器,也就是NPU集成在MCU上,可以更好地满足不同的应用场景需求。前一篇文章我们谈到了一些MCU厂商已经在其产品中集成了NPU内核,其中有些厂商,比如ST,NXP等都是采用自研的NPU IP内核,那么市场上有没有第三方的NPU IP产品可供MCU厂商选择呢?答案是有的,下面是芯查查统计的市面上可供选择的NPU IP产品。 Arm Ethos NPU:已推出第三代,有20家合作伙伴 Arm比较早就注意到了边缘AI的市场需求,并在2020年初正式推出微神经网络处理器(Micro Neural Network Processing Unit)Ethos-U55,正式开启MCU AI时代来临,不过由于新冠疫情影响,直到2022年底,其合作伙伴ALIF Semiconductor才推出第一颗实体芯片Ensemble系列(E1/E3/E5/E7)及配套开发板。 如今,Arm的NPU产品已经推出三代了,除了此前推出的Ethos-U55与Ethos-U65,今年4月份还推出了Ethos-U85。其中,Ethos-U85 是 Arm Ethos-U 产品线中的第三代 NPU,也是迄今为止性能和能效最强的 Ethos NPU。与上一代产品Ethos-U65相比,该 NPU 的性能提升了4倍,能效提高了 20%,并且可在主流网络上实现高达 85% 的利用率。全新 Ethos-U85 可满足诸如工厂自动化和商用或智能家居摄像头等物联网应用不断攀升的性能需求。此外,其专为搭配基于 Cortex-M 或 Cortex-A的系统一同运行而设计,并容忍高 DRAM 延迟。 图:Arm Ethos-U85支持Transformer架构和卷积神经网络(来源:Arm) Ethos-U85 的主要特性包括: 单周期支持从 128 到 2048 个 MAC单元的配置——在 1GHz 时,算力可支持从 256 GOPS 到 4 TOPS。 支持 int8 权重和 int8 或 int16 激活。 支持 Transformer 架构网络,以及 CNN 和 RNN。 硬件原生支持 2/4 稀疏性,使吞吐量翻倍。 内部 SRAM 为 29 至 267 KB,多达六个 128 位 AXI5 接口。 支持权重压缩,采用标准和快速权重编码器。 支持扩展压缩。 图:Arm推出的三代NPU IP规格对比(来源:Arm) 除了 Ethos-U55 和 Ethos-U65 目前支持的算子,通过支持 TRANSPOSE、GATHER、MATMUL、RESIZE BILINEAR 和 ARGMAX 等运算,Ethos-U85 涵盖了对 Transformer 模型和 DeeplabV3 语义分割网络的原生硬件支持。 Ethos-U85 也支持元素级算子链化。通过链化将元素级运算与先前的运算相结合,使 SRAM 不必先写入再读取中间张量。由此可凭借 NPU 和内存之间数据传输量的减少,提高 NPU 的效率。相比于 Ethos-U65,链化是 Ethos-U85 在效率提升上的新功能之一,其余还包括快速的权重编码器、优化的 MAC 阵列能效,以及提升的元素效率。 到今年已经有ALIF、Himax(奇景)、Nuvoton(新唐)、Infineon(英飞凌)推出了基于Cortex-M55+Ethos-U55组合的产品。据悉,Arm Ethos NPU系列产品已经有超过20家授权许可合作伙伴,其中ALIF和英飞凌是全新的Arm Ethos-U85 NPU的早期采用者。 安谋科技:周易NPU系列 2023年3月份,安谋科技发布了自研新一代AI处理器“周易”X2 NPU。据其官网介绍,该NPU采用了第三代“周易”架构,支持多核Cluster,最高可达320TOPS子系统。实时的硬件任务管理使得“周易”X2 NPU可实现最高千万次/秒的任务调度,将各个计算单元的效能发挥到最佳。 在算力大幅提升的同时,“周易”X2 NPU还具有更高的精度和灵活性。在精度方面,“周易”X2 NPU支持int4 / int8 / int12 / int16 / int32,fp16 / bf16 / fp32多精度融合计算,计算效率与计算密度得到显著提升。 图:安谋科技的NPU架构(来源:芯查查拍摄) 在灵活性方面,“周易”X2 NPU在支持自定义算子、满足各种模型部署需求的基础上,还面向各类应用场景提供定制化AI解决方案,以进一步满足客户在智能驾驶、手机影像AI处理、人机交互等场景中的差异化需求。 “周易”X2 NPU特别针对ADAS、智能座舱、平板电脑、台式机和手机等细分应用场景进行了大量性能优化,可大幅提升手机拍照、录像中的高分辨率图像处理能力,以及车载中常用的Transformer等应用的性能,同时采用i-Tiling技术大幅减少带宽需求,进一步提升计算效率,让客户能更轻松地应对不断迭代的多样化计算需求。 图:周易Z系列NPU特性(来源:安谋科技) 此外,安谋科技还有“周易”Z系列NPU,采用为神经网络运行及相应的前后处理设计的专用指令集,具有均衡的可编程能力和优化的标准处理能力,满足不同人工智能算法需求。融合了多种执行粒度的指令,可以为人工智能提供能效比高的运算能力。"周易" Z 系列 NPU 也支持配合 Arm Cortex CPU、Arm Mali GPU 以及第三方硬件的异构计算,能够大大提高人工智能应用开发的生产效率。目前,“周易”Z 系列已经推出了 Z1、Z2 和 Z3 三代产品。 Ceva:可提供一整套边缘AI处理器解决方案 Ceva有一整套专为边缘AI和传感应用而定制的可扩展处理器解决方案,算力从10GOPS到1000TOPS的NPU到DSP可供选择。 具体产品包括Ceva-NeuPro-Nano、Ceva-NeuPro-M、Ceva-NeuPro Studio等。其中,Ceva-NeuPro-Nano 是一款高效自给式边缘 NPU,专为 TinyML 应用设计,适用于 AIoT 设备。其性能范围从 10 GOPS 到 200 GOPS,支持电池供电设备的常时开启应用,如可听设备、可穿戴设备、家庭音频、智能家居和智能工厂。无需主CPU/DSP,即可独立运行,包括代码执行和内存管理。它支持 4、8、16 和 32 位数据类型,具有原生 Transformer 计算、稀疏性加速和快速量化功能。通过 Ceva-NetSqueeze 技术,内存占用减少 80%。提供 Ceva NeuPro-Studio AI SDK,与 TFLM 和 µTVM 等开源 AI 推理框架无缝协作,涵盖语音、视觉和传感用例。Ceva-NPN32 和 Ceva-NPN64 两种配置满足广泛的应用需求,提供最佳功耗效率和小巧硅面积。 Cadence:Tensilica Neo NPU IP Cadence推出的Neo NPU IP扩展能力很强,可为低功耗应用提供广泛的AI功能。Neo NPU单核配置的性能高达 80 TOPS,支持经典 AI 模型和最新的生成式 AI 模型,配有简单易用的可扩展 AMBA AXI 互联,可处理来自任何处理器的 AI/ML 负载,包括应用处理器、通用型微处理器和 DSP。NeuroWeave Software Development Kit(SDK)是对 AI 硬件的补充,为开发人员提供了一站式 AI 软件解决方案,涵盖 Cadence AI 和 Tensilica IP 产品,用于实现“零代码”AI 开发。 其主要特性包括: 可扩展性:单核解决方案可从 8 GOPS 扩展到 80 TOPS,多核可进一步扩展到数百 TOPS。 广泛的配置范围:每个周期支持 256 到 32K 个 MAC,允许 SoC 架构师优化其嵌入式 AI 解决方案,以满足功耗、性能和面积(PPA)权衡的要求。 集成支持各种网络拓扑结构和运营商:可高效运行来自任何主处理器(包括 DSP、通用型微控制器或应用处理器)的推理任务,从而显著提高系统性能,降低功耗。 易于部署:加快产品上市,满足日新月异的新一代视觉、音频、雷达、自然语言处理(NLP)和生成式 AI 流水线的需求。 灵活性:支持 Int4、Int8、Int16 和 FP16 数据类型,涵盖构成 CNN、RNN 和基于 Transformer 的网络基础的各种操作,可灵活权衡神经网络的性能和准确性。 高性能和高效率:与第一代 Cadence AI IP 相比,性能最多可提高 20 倍,每面积每秒推理次数(IPS/mm2)提高 2-5 倍,每瓦每秒推理次数(IPS/W)提高 5-10 倍。 芯原:采用其NPU IP的AI类芯片出货量超过1亿颗 芯原在今年年初的时候发布新闻稿宣称,集成了其NPU IP的AI芯片在全球范围内出货量超过了1亿颗,主要应用在物联网、可穿戴、智能家居、安防监控、服务器、汽车电子、智能手机、平板电脑等市场。据悉,其NPU IP已被72家客户用在了128款AI芯片当中。 其最新推出的VIP9000系列NPU IP提供了可扩展和高性能的处理能力,适用于Transformer和卷积神经网络(CNN)。结合芯原的Acuity工具包,这款强大的IP支持含PyTorch、ONNX和TensorFlow在内的所有主流框架。 此外,它还具备4位量化和压缩技术,以解决带宽限制问题,便于在嵌入式设备上部署生成式人工智能(AIGC)和大型语言模型(LLM)算法,如Stable Diffusion和Llama 2。 VIP9000系列支持从0.5TOPS到20TOPS的性能范围,适用于从可穿戴设备、物联网、智能家居到汽车和边缘服务器等广泛应用。 Synopsys:ARC NPX6 NPU IP 系列 Synopsys ARC NPX6 NPU IP 系列是业内性能最高的神经处理单元(NPU)IP,专为满足AI应用的实时计算需求而设计,具备超低功耗。该系列包含ARC NPX6和NPX6FS,支持最新的复杂神经网络模型,包括生成式AI,并提供高达3,500 TOPS的性能,适用于智能SoC设计。 ARC NPX6 NPU IP单实例在5nm工艺下能提供高达250 TOPS的性能,通过稀疏特性可提升至440 TOPS。集成多个NPU实例后,性能可达3,500 TOPS。ARC NPX6支持从1K到96K MACs,兼容CNN、RNN/LSTM及新兴网络如Transformer。它支持INT 4/8/16位分辨率,并可选BF16和FP16。 ARC NPX6FS NPU IP专为功能安全设计,符合ISO 26262 ASIL D标准,适用于汽车和其他需要高安全性的应用。它具备双核锁步处理器和自检安全监控,满足混合关键性和虚拟化需求。 Synopsys提供的ARC MetaWare MX开发工具包包含编译器、调试器、神经网络软件开发工具包(SDK)、虚拟平台SDK、运行时和库以及高级仿真模型。该工具包能自动将算法划分到MAC资源上,实现高效处理,简化了开发流程。 ARC NPX6 NPU IP系列广泛应用于智能相机、传感器融合、工业自动化、汽车电子和高性能嵌入式系统等领域,助力实现智能SoC设计中的AI创新。 英业达:为低性能MCU量身定制的NPU 英业达正积极发力各种边缘AI运算应用领域,该公司在2023年Q1推出了完整的一站式AI IP导入服务,以及“VectorMesh” AI 加速器。为满足MCU领域的AI需求,英业达还推出了定位于超低逻辑门数 (Gate Count) 的NPU (neural processing unit) IP—— Minima 系列。 Minima 系列为满足终端算力需求在 32 GOPS以下的应用,从8051 MCU到各家 32/64位RISC CPU都可以搭配使用,没有整合限制。 实际应用则可用于物体检测、特征检测、人脸检测、人脸识别、姿态识别、图像分割、图像美化、信号过滤等应用。对MCU市场的少量多样特性,英业达除了陆续推出各种低算力要求的 NN 模型库供客户选择使用,也接受客户提案,提供 turnkey 定制化设计服务。 据悉,除了Minima系列外,英业达还将推出复杂度更高,以及终端算力更大的Parva和Magna系列,同样都具备低功耗、高效能、高弹性架构等3大特点,应用于边缘端 AI推理,力求满足多元化市场需求。 结语 随着数据量的爆炸式增长,如何有效利用这些数据成为了新的挑战。边缘AI的出现解决了这个问题,它允许设计人员利用现有的数据创建更优的应用。边缘AI的核心在于能够在云端设计和训练模型,然后在嵌入式设备上运行这些模型,实现数据处理的本地化。 当然,除了上面提到的可供第三方选择的NPU IP可以用于MCU,其实最近几年也涌现出了不少基于RISC-V内核的NPU IP也是值得关注的,如果对这块感兴趣可以关注我们的后续文章。
MCU
芯查查 . 2024-11-11 6 1 8531

Melexis发布突破性Arcminaxis位置感应技术及产品,专为机器人关节打造
Melexis 宣布推出突破性磁性技术Arcminaxis™。这一技术专为满足市场对经济实惠且高精度机器人关节位置感应解决方案需求的日益增长而设计。首款搭载Arcminaxis™技术的产品MLX90384,通过简化机器人关节的组装流程,为制造商提供高效益低成本的解决方案。该产品附带支持校准和高效操作的磁铁及软件包,为设计提供简便性和经济性。 在以往机器人的设计方案中,制造商往往优先考虑性能顶尖的传感器芯片,而对成本因素的考量则相对不足。 但是随着机器人应用的不断拓展,制造商愈发重视在提升生产效率的同时降低成本,这使得他们在选择组件时更加谨慎,以确保设计的经济性与简便性,同时维持机器人的高可靠性和精确的运动重复性。 Arcminaxis™系列的首秀之作 MLX90384作为迈来芯Arcminaxis™系列的首秀之作,成功将卓越的性能与极致的经济性相结合,巧妙地在高性能但成本昂贵的光学解决方案与成本低廉但效果欠佳的偶极磁性解决方案之间找到一个理想的平衡点,以解决上述的挑战。 MLX90384的核心优势在于其创新的磁铁设计和卓越的感应能力 与常规的多极磁铁传感器芯片不同,MLX90384打破了磁极尺寸与传感器芯片必须严格匹配的局限。这一特性使得采用更大、磁力更强的磁铁成为可能,从而能够输出更强信号并支持更大的操作间隙。更重要的是,同一传感器芯片能够灵活匹配不同尺寸的磁铁。因此,Arcminaxis™技术集成了以下独特且关键的性能组合:高达18位的分辨率、±0.5mm宽松的磁铁与传感器芯片放置公差以及标称1.5mm的磁铁与芯片间距。 在机器人设计领域中,MLX90384凭借其功能优势,有效降低传感器芯片和磁铁的成本。与现有的多极解决方案相比,MLX90384不仅设计和组装流程更为便捷,还因其更大的装配公差和更强的机械磨损抵抗力而脱颖而出。MLX90384采用TSSOP-16封装,提供磁铁、操作系统及校准工具的软件包。此外,迈来芯的Arcminaxis™技术通过支持偏轴、贯穿轴和线性编码器等应用场景,进一步提升设计的灵活性。 Melexis市场经理Atanas Dikov表示:“随着MLX90384的全新亮相,迈来芯能够提供以应用为导向的前瞻性解决方案,为下一代机器人实现性能与成本之间的理想平衡,这款产品标志着迈来芯创新Arcminaxis™系列的开端,未来我们将推出更多专为机器人领域量身定制的解决方案。”
传感器
迈来芯Melexis . 2024-11-11 1650

思特威荣获2024全球电子成就奖双料大奖,董事长徐辰博士获选“年度亚太最佳管理者
2024年11月5日,国际集成电路展览会暨研讨会在深圳隆重举行。思特威创始人兼首席执行官徐辰博士受邀出席全球CEO峰会并发表了精彩演讲。在同期举办的2024全球电子成就奖(WEAA)颁奖典礼上,思特威旗舰级手机图像传感器SC580XS蝉联“年度最佳传感器”大奖,董事长徐辰博士获选“年度亚太最佳管理者”。 双料大奖,全面实力肯定 全球电子成就奖(WEAA)是全球电子技术领域领先媒体集团AspenCore主办的年度全球性电子技术行业奖项,获奖者皆是由资深产业分析师组成的评审委员会以及来自亚、美、欧洲的全球网站用户群共同评选而来。WEAA作为全球电子技术与半导体领域最具权威性和影响力的奖项之一,旨在评选并表彰对推动全球电子产业创新做出杰出贡献的企业和管理者,各类奖项获得提名的企业、管理者和产品均为创造了不凡成就的行业领先者。 年度亚太最佳管理者大奖是产业分析师推荐奖的最重磅奖项之一,一直备受业界关注。思特威创始人兼首席执行官徐辰博士凭借先进的技术创新成就、领先的产品市场操盘策略与卓越的组织运营管理建设能力,荣获“2024年度亚太最佳管理者”称号。 徐辰先生毕业于清华大学电子工程系,并于香港科技大学先后取得电机及电子工程学硕士和博士学位,在CMOS图像传感器领域拥有二十余年产品研发与团队领导经验,高度重视技术研发创新。在他的带领下,思特威不断推动CIS产品技术升级,成功在安防监控、智能手机、车载电子、机器视觉等多元领域开发了高性能、系列化的CMOS图像传感器产品,市场表现名列前茅。据 TSR 报告显示,目前思特威在全球 CIS 市场的出货量位列前五,安防 CIS 市占率全球第一,且在智能手机 CIS 及车载 CIS 等领域均跻身全球厂商第一梯队。 此外,思特威更凭借面向旗舰级智能手机主摄推出的5000万像素高性能图像传感器SC580XS,蝉联了WEAA年度最佳传感器大奖。 WEAA年度最佳传感器奖、WEAA年度亚太最佳管理者奖 全球电子成就奖年度双料大奖的获得,是思特威于CMOS图像传感器领域取得卓越进展和非凡成就的最佳印证,代表了全球电子科技领域权威媒体与行业对思特威全面实力的高度认可,更意味着以SC580XS产品为代表的思特威手机CIS产品已在高端手机图像传感器领域成功占据了一席之地。 多元视界,影像革新 本次全球CEO峰会上,思特威创始人兼首席执行官徐辰博士受邀出席并发表了精彩演讲。徐辰博士为大家深入介绍了CMOS图像传感器在智能安防、智能手机、车载电子等多个重点领域的前沿技术与发展趋势。 思特威创始人兼首席执行官徐辰博士发表精彩演讲 徐辰博士提到,CMOS图像传感器在多领域的应用上,正呈现向高品质高性能迭代升级的趋势。在智能手机领域,移动影像已迈入专业化时代,过往专业相机才能够实现的效果与功能,现在都已逐渐移植到手机移动影像中来。这样的变化对手机CMOS图像传感器能力提出了更高的要求。针对于此,思特威手机CIS产品不断推动着更高分辨率、更高动态范围、更快对焦速度、更低耗等多方面的核心性能提升,为高端旗舰级智能手机的影像发展注入了强大的动力。 在车载领域,思特威车载CIS凭借高动态范围、高分辨率和优异的夜视效果等优势,为智能驾驶系统提供更加及时实时、准确的图像信息,让人们的出行更加便捷、安全、高效。此外,在安防领域,徐辰博士为大家介绍了安防CIS两大主流功能趋势,黑光夜视全彩与全时录像(AOV, Always-On Video)。采用黑光夜视全彩方案的摄像头可以实现夜晚拍摄出接近白天的全彩效果。AOV全时录像则可以在没有事件触发时候以超低功耗录制,有异动时立刻启动以正常帧率录制,从而覆盖24小时全天候的监测的应用需求。 年度最佳传感器,旗舰级质感影像 本次荣获全球电子成就奖年度最佳传感器的SC580XS是思特威专为旗舰级智能手机主摄打造的5000万像素高性能图像传感器。基于22nm HKMG Stack工艺制程,SC580XS拥有1/1.28英寸的光学尺寸,搭载了思特威最新一代SFCPixel®-2像素技术,并采用了PixGain HDR®、AllPix ADAF®等多项创新技术和工艺。 凭借先进的PixGain HDR®技术和SFCPixel®-2技术,思特威SC580XS实现了动态范围的大幅提升和图像噪声的显著降低,能够助力手机摄像头清晰地捕捉到暗光场景下画面的丰富细节,打造色彩真实、无惧明暗的全天候高清影像,让移动影像质感进一步跃升。 基于AllPix ADAF®和Sparse PDAF技术,SC580XS支持100%全像素对焦(暗光场景)和部分像素对焦(日常光线场景)双模式自由切换,不仅能为手机摄像头带来更快速精准的对焦效果,实现疾速高清抓拍,还能大幅节省自身功耗。 思特威始终专注于高端成像技术的创新与研发,积极探索与拓展影像能力边界,将不断以更高性能的系列化产品,为智能安防、智能手机、车载电子与机器视觉等多元视觉领域带来全面影像体验提升。思特威期待与广大产业链伙伴一起深入探索影像技术,共创非凡“视”界。
思特威 . 2024-11-11 1 9807

新品!米尔RK3576核心板8核6T高算力,革新AIoT设备
随着科技的快速发展,AIoT智能终端对嵌入式模块的末端计算能力、数据处理能力等要求日益提高。近日,米尔电子发布了一款基于瑞芯微RK3576核心板和开发板。核心板提供4GB/8GB LPDDR4X、32GB/64GB eMMC等多个型号供选择。瑞芯微RK3576核心优势主要包括高性能数据处理能力、领先的AI智能分析、多样化的显示与操作体验以及强大的扩展性与兼容性。下面详细介绍这款核心板的优势。 6 TOPS超强算力,8核CPU赋能AI 瑞芯微RK3576搭载了四核A72与四核A53处理器,主频高达2.2GHz,确保了系统的高效运行和强大的计算能力。RK3576集成了6TOPS的NPU,支持多种深度学习框架,能够处理复杂的AI算法,提高监控效率,降低误报率。 AI算力强,搭载6 TOPS的NPU加速器,3D GPU,赋能工业AI 三屏异显,丰富多媒体功能 RK3576支持三屏异显,最高支持4K分辨率的视频显示,提供清晰的视觉体验。它还支持8K分辨率的硬解码,满足多场景多样化的显示需求。此外,RK3576的灵活VOP设计允许根据实际需求调整视频输出配置,提升系统的适用性和易用性。 丰富的接口,强大的扩展性和兼容性 RK3576拥有双千兆以太网接口、PCIE2.1、USB3.2、SATA3、DSMC/Flexbus、CANFD、UART等丰富接口,具备强大的扩展性和兼容性,支持大模型运行和多模态检索功能,处理复杂的监控数据和场景信息。它还支持512Mbps的接入、转发和存储能力,确保数据的高效传输和存储。 米尔RK3576核心板采用LGA创新设计,可靠性高,又能节省连接器成本。 高可靠性保证,严格的测试标准,保障产品高质量 国产核心板,应用场景丰富 专为新一代电力智能设备、工业互联网设备、工业控制设备、工业机器人、商显、触控一体机、工程机械、轨道交通等行业设计 米尔基于瑞芯微3576核心板及开发板配置型号 核心板产品型号 主芯片 内存 存储器 工作温度 MYC-LR3576-32E4D-220-C RK3576 4GB LPDDR4X 32GB eMMC 0℃~+70℃ 商业级 MYC-LR3576-64E8D-220-C RK3576 8GB LPDDR4X 64GB eMMC 0℃~+70℃ 商业级 MYC-LR3576J-32E4D-160-I RK3576J 4GB LPDDR4X 32GB eMMC -40℃~+85℃ 工业级 MYC-LR3576J-64E8D-160-I RK3576J 8GB LPDDR4X 64GB eMMC -40℃~+85℃ 工业级 开发板产品型号 对应核心板型号 工作温度 MYD-LR3576-32E4D-220-C MYC-LR3576-32E4D-220-C 0℃~+70℃ 商业级 MYD-LR3576-64E8D-220-C MYC-LR3576-64E8D-220-C 0℃~+70℃ 商业级 MYD-LR3576J-32E4D-160-I MYC-LR3576J-32E4D-160-I -40℃~+85℃ 工业级 MYD-LR3576J-64E8D-160-I MYC-LR3576J-64E8D-160-I -40℃~+85℃ 工业级 产品链接: https://www.myir.cn/shows/151/81.html 天猫链接: https://detail.tmall.com/item.htm?id=846168356626
瑞芯微RK3576
米尔电子 . 2024-11-11 9935

奥迪集成恩智浦UWB产品组合,打造无感数字钥匙解决方案!
奥迪采用了恩智浦Trimension NCJ29Dx系列超宽带(UWB)精密测距IC,增强其全新高端电动平台(PPE)的智能、无感数字钥匙功能 Trimension NCJ29Dx系列旨在提供强大、精确和安全的测距和连接,满足全球汽车OEM遵循车联网联盟(CCC)的标准部署智能安全门禁的需求 奥迪与保时捷联合开发的PPE为下一代电动汽车奠定了基础 恩智浦半导体宣布,其丰富的UWB产品组合中的Trimension NCJ29Dx系列,为奥迪先进的新一代UWB平台奠定技术基础,提供精确、安全的实时定位功能,从而可通过智能移动设备和其他基于UWB的功能实现无感数字钥匙,满足行业领先的高端汽车制造商的需求。搭载恩智浦Trimension UWB设备的汽车(包括奥迪Q6 e-tron)将于2024年上市。 智能安全汽车门禁基于恩智浦广泛的Trimension UWB产品组合提供的精密测距功能,可精确识别驾驶员相对于汽车的位置,只有当驾驶员靠近汽车时才能解锁车门。驾驶员可以使用支持UWB的手机或可穿戴设备上的数字钥匙来解锁和启动汽车,手机或可穿戴设备放在驾驶员的口袋或包里即可实现,整个过程无需手动操作。 奥迪股份公司车身电子开发部主管Ulf Warschat表示: “奥迪长期以来一直走在汽车技术的前沿,新一代支持UWB的平台也不例外。恩智浦Trimension UWB产品组合能够提供精确、安全的实时定位功能,确保驾驶员可以享受到一系列先进的特性和功能,获得全新的驾驶体验。” 恩智浦半导体资深副总裁兼安全汽车门禁总经理Markus Staeblein表示: “恩智浦久经考验的Trimension UWB平台能够帮助OEM为驾驶员提供新功能,轻松安全实现免手动开关车门,并支持各种其他用例,如自动电动汽车充电等。凭借我们在车联网联盟(CCC)和FiRa联盟等机构中的专业知识和标准化工作,UWB将继续推动消费者汽车体验的全新提升,并迅速成为汽车生态系统中的重要组成部分。” Trimension NCJ29Dx系列属于恩智浦安全汽车门禁系统解决方案产品组合,其中还包括NCF3340 NFC控制器和KW37蓝牙5.0长距离MCU。奥迪在其新平台中也采用了这些设备。 Trimension NCJ29Dx系列支持基于UWB的精密测距功能,遵循IEEE 802.15.4、CCC和FiRa标准。它能够为电池供电设备(如遥控钥匙)提供较高的定位精度和功率优化,同时最大限度地降低BOM成本。此外,它还可提供较高级别的保护,防止通过中继攻击进行的汽车盗窃,并且片上支持多种加密操作。 Trimension NCJ29Dx系列属于丰富的UWB产品组合,产品组合广泛应用于汽车、移动、物联网、工业领域。Trimension NCJ29D6等产品结合UWB精密测距与UWB雷达功能,允许OEM通过单一系统承载多种用例,包括智能、安全汽车门禁、儿童存在检测、入侵警报、脚踢感应等。
NXP
NXP客栈 . 2024-11-08 4 2 1725

炬芯科技周正宇:Actions Intelligence 端侧AI音频芯未来
ChatGPT激发了人们的好奇心也打开了人们的想象力,伴随着生成式AI(Generative AI)以史无前例的速度被广泛采用,AI算力的需求激增。与传统计算发展路径类似,想让AI普及且发掘出AI的全部潜力,AI计算必须合理的分配在云端服务器和端侧装置(如PC,手机,汽车, IoT装置),而不是让云端承载所有的AI负荷。这种云端和端侧AI协同作战的架构被称为混合AI(Hybrid AI),将提供更强大,更有效和更优化的AI。换句话说,要让AI真正触手可及,深入日常生活中的各种场景,离不开端侧AI的落地。 端侧AI将机器学习带入每一个IoT设备,减少对云端算力的依赖,可在无网络连接或者网络拥挤的情况下,提供低延迟AI体验,还具备低功耗、高数据隐私性和个性化等显著优势。AIoT的一个最重要载体是电池驱动的超低功耗小型IoT设备,其数量庞大且应用丰富,在新一代AI的浪潮中,端侧AI是实现人工智能无处不在的关键,而为电池驱动的低功耗IoT装置赋能AI又是让端侧AI变为现实的关键。 2024年11月5日,炬芯科技股份有限公司董事长兼CEO周正宇博士受邀出席Aspencore2024全球CEO峰会,结合AI时代热潮及端侧AI所带来的新一代AI趋势,分享炬芯科技在低功耗端侧AI音频的创新技术及重磅产品,发表主题演讲:《Actions Intelligence: 端侧AI音频芯未来》。 周正宇博士表示:在从端侧AI到生成式AI的广泛应用中,不同的AI应用对算力资源需求差异显著,而许多端侧AI应用是专项应用, 并不需要大模型和大算力。尤其是以语音交互,音频处理,预测性维护,健康监测等为代表的AIoT领域。 炬芯科技目标是在电池驱动的中小模型机器学习IoT设备上实现高能效的AI算力 在便携式产品和可穿戴产品等电池驱动的IoT设备中,炬芯科技致力于在毫瓦级功耗下实现TOPS级别的AI算力,以满足IoT设备对低功耗、高能效的需求。以穿戴产品(耳机和手表)为例,平均功耗在10mW-30mW之间,存储空间在10MB以下,这框定了低功耗端侧AI,尤其是可穿戴设备的资源预算。 周正宇博士指出“Actions Intelligence”是针对电池驱动的端侧AI落地提出的战略,将聚焦于模型规模在一千万参数(10M)以下的电池驱动的低功耗音频端侧AI应用,致力于为低功耗AIoT装置打造在10mW-100mW之间的功耗下提供0.1-1TOPS的通用AI算力。也就是说“Actions Intelligence”将挑战目标10TOPS/W-100TOPS/W的AI算力能效比。根据ABI Research预测,端侧AI市场正在快速增长,预计到2028年,基于中小型模型的端侧AI设备将达到40亿台,年复合增长率为32%。到2030年,预计75%的这类AIoT设备将采用高能效比的专用硬件。 现有的通用CPU和DSP解决方案虽然有非常好的算法弹性,但是算力和能效远远达不成以上目标,依据ARM和Cadence的公开资料,同样使用28/22nm工艺,ARM A7 CPU 运行频率1.2GHz时可获取0.01TOPS的理论算力,需要耗电100mW,即理想情况下的能效比仅为0.1TOPS/W;HiFi4 DSP运行600MHz时可获取0.01TOPS的理论算力,需要耗电40mW,即理想情况下的能效比0.25TOPS/W。即便专用神经网路加速器(NPU)的IP ARM周易能效比大幅提升,但也仅为2TOPS/W。 以上传统技术的能效比较差的本质原因均源于传统的冯•诺依曼计算结构。传统的冯•诺伊曼计算系统采用存储和运算分离的架构,存在“存储墙”与“功耗墙”瓶颈,严重制约系统算力和能效的提升。 在冯•诺伊曼架构中,计算单元要先从内存中读取数据,计算完成后,再存回内存。随着半导体产业的发展和需求的差异,处理器和存储器二者之间走向了不同的工艺路线。由于工艺、封装、需求的不同,存储器数据访问速度跟不上处理器的数据处理速度,数据传输就像处在一个巨大的漏斗之中,不管处理器灌进去多少,存储器都只能“细水长流”。两者之间数据交换通路窄以及由此引发的高能耗两大难题,在存储与运算之间筑起了一道“存储墙”。 此外,在传统架构下,数据从内存单元传输到计算单元需要的功耗是计算本身的许多倍,因此真正用于计算的能耗和时间占比很低,数据在存储器与处理器之间的频繁迁移带来严重的传输功耗问题,称为“功耗墙”。 基于SRAM的存内计算是目前低功耗端侧AI的最佳解决方案 周正宇博士表示:弱化或消除“存储墙”及“功耗墙”问题的方法是采用存内计算Computing-in-Memory(CIM)结构。其核心思想是将部分或全部的计算移到存储中,让存储单元具有计算能力,数据不需要单独的运算部件来完成计算,而是在存储单元中完成存储和计算,消除了数据访存延迟和功耗,是一种真正意义上的存储与计算融合。同时,由于计算完全依赖于存储,因此可以开发更细粒度的并行性,大幅提升性能尤其是能效比。 机器学习的算法基础是大量的矩阵运算,适合分布式并行处理的运算,存内计算非常适用于人工智能应用。 要在存储上做计算,存储介质的选择是成本关键。单芯片为王,炬芯的目标是将低功耗端侧AI的计算能力和其他SoC的模块集成于一颗芯片中,于是使用特殊工艺的DDR RAM和Flash无法在考虑范围内。而采用标准SoC适用的CMOS工艺中的SRAM和新兴NVRAM(如RRAM或者MRAM)进入视野。SRAM工艺非常成熟,且可以伴随着先进工艺升级同步升级,读写速度快、能效比高,并可以无限多次读写。唯一缺陷是存储密度较低,但对于绝大多数端侧AI的算力需求,该缺陷不会成为阻力。短期内,SRAM是在低功耗端侧AI设备上打造高能效比的最佳技术路径,且可以快速落地,没有量产风险。 长期来看,新兴NVRAM 如RRAM由于密度高于SRAM,读功耗低,也可以集成入SoC,给存内计算架构提供了想象空间。但是RRAM工艺尚不成熟,大规模量产依然有一定风险,制程最先进只能到22nm,且存在写次数有限的致命伤(超过会永久性损坏)。故周正宇博士预期未来当RRAM技术成熟以后,SRAM 跟RRAM的混合技术有机会成为最佳技术路径,需要经常写的AI计算可以基于SRAM的CIM实现,不经常或者有限次数写的AI计算由RRAM的CIM实现,基于这种混合技术有望实现更大算力和更高的能效比。 炬芯科技创新性采用模数混合设计实现基于SRAM的存内计算(CIM) 业界公开的基于SRAM的CIM电路有两种主流的实现方法,一是在SRAM尽量近的地方用数字电路实现计算功能, 由于计算单元并未真正进入SRAM阵列,本质上这只能算是近存技术。另一种思路是在SRAM介质里面利用一些模拟器件的特性进行模拟计算,这种技术路径虽然实现了真实的CIM,但缺点也很明显。一方面模拟计算的精度有损失,一致性和可量产性完全无法保证,同一颗芯片在不同的时间不同的环境下无法确保同样的输出结果。另一方面它又必须基于ADC和DAC来完成基于模拟计算的CIM和其他数字模块之间的信息交互,整体数据流安排以及界面交互设计限制多,不容易提升运行效率。 炬芯科技创新性的采用了基于模数混合设计的电路实现CIM,在SRAM介质内用客制化的模拟设计实现数字计算电路,既实现了真正的CIM,又保证了计算精度和量产一致性。 周正宇博士认为,炬芯科技选择基于模数混合电路的SRAM存内计算(Mixed-Mode SRAM based CIM,简称MMSCIM)的技术路径,具有以下几点显著的优势: 第一,比纯数字实现的能效比更高,并几乎等同于纯模拟实现的能效比; 第二,无需ADC/DAC, 数字实现的精度,高可靠性和量产一致性,这是数字化天生的优势; 第三,易于工艺升级和不同FAB间的设计转换; 第四,容易提升速度,进行性能/功耗/面积(PPA)的优化; 第五,自适应稀疏矩阵,进一步节省功耗,提升能效比。 而对于高质量的音频处理和语音应用,MMSCIM是最佳的未来低功耗端侧AI音频技术架构。由于减少了在内存和存储之间数据传输的需求,它可以大幅降低延迟,显著提升性能,有效减少功耗和热量产生。对于要在追求极致能效比电池供电IoT设备上赋能AI,在每毫瓦下打造尽可能多的 AI 算力,炬芯科技采用的MMSCIM技术是真正实现端侧AI落地的最佳解决方案。 周正宇博士首次公布了炬芯科技MMSCIM路线规划,从路线图中显示: 1、炬芯第一代(GEN1)MMSCIM已经在2024年落地, GEN1 MMSCIM采用22 纳米制程,每一个核可以提供100 GOPS的算力,能效比高达6.4 TOPS/W @INT8; 2、到 2025 年,炬芯科技将推出第二代(GEN2)MMSCIM,GEN2 MMSCIM采用22 纳米制程,性能将相较第一代提高三倍,每个核提供300GOPS算力,直接支持Transformer模型,能效比也提高到7.8TOPS/W @INT8; 3、到 2026 年,推出新制程12 纳米的第三代(GEN3)MMSCIM,GEN3 MMSCIM每个核达到1 TOPS的高算力,支持Transformer,能效比进一步提升至15.6TOPS/W @INT8。 以上每一代MMSCIM技术均可以通过多核叠加的方式来提升总算力,比如MMSCIM GEN2单核是300 GOPS算力,可以通过四个核组合来达到高于1TOPS的算力。 炬芯科技正式发布新一代基于MMSCIM端侧AI音频芯片 炬芯科技成功落地了第一代MMSCIM在500MHz时实现了0.1TOPS的算力,并且达成了6.4TOPS/W的能效比,受益于其对于稀疏矩阵的自适应性,如果有合理稀疏性的模型(即一定比例参数为零时),能效比将进一步得到提升,依稀疏性的程度能效比可达成甚至超过10TOPS/W。基于此核心技术的创新,炬芯科技打造出了下一代低功耗大算力、高能效比的端侧AI音频芯片平台。 周正宇博士代表炬芯科技正式发布全新一代基于MMSCIM端侧AI音频芯片,共三个芯片系列: 第一个系列是ATS323X,面向低延迟私有无线音频领域; 第二个系列是ATS286X,面向蓝牙AI音频领域; 第三个系列是ATS362X,面向AI DSP领域。 三个系列芯片均采用了CPU(ARM)+ DSP(HiFi5)+ NPU(MMSCIM)三核异构的设计架构,炬芯的研发人员将MMSCIM和先进的HiFi5 DSP融合设计形成了炬芯科技“Actions Intelligence NPU(AI-NPU)”架构,并通过协同计算,形成一个既高弹性又高能效比的NPU架构。在这种AI-NPU架构中MMSCIM支持基础性通用AI算子,提供低功耗大算力。同时,由于AI新模型新算子的不断涌现,MMSCIM没覆盖的新兴特殊算子则由HiFi5 DSP来予以补充。 以上全部系列的端侧AI芯片,均可支持片上1百万参数以内的AI模型,且可以通过片外PSRAM扩展到支持最大8百万参数的AI模型,同时炬芯科技为AI-NPU打造了专用AI开发工具“ANDT”,该工具支持业内标准的AI开发流程如Tensorflow,HDF5,Pytorch和Onnx。同时它可自动将给定AI算法合理拆分给CIM和HiFi5 DSP去执行。ANDT是打造炬芯低功耗端侧音频AI生态的重要武器。借助炬芯ANDT工具链轻松实现算法的融合,帮助开发者迅速地完成产品落地。 根据周正宇博士公布的第一代MMSCIM和HiFi5 DSP能效比实测结果的对比显示: 当炬芯科技GEN1 MMSCIM与HiFi5 DSP均以500MHz运行同样717K参数的Convolutional Neural Network(CNN)网路模型进行环境降噪时,MMSCIM相较于HiFi5 DSP可降低近98%功耗,能效比提升达44倍。而在测试使用935K 参数的CNN网路模型进行语音识别时,MMSCIM相较于HiFi5 DSP可降低93%功耗,能效比提升14倍。 另外,在测试使用更复杂的网路模型进行环境降噪时,运行Deep Recurrent Neural Network模型时,相较于HiFi5 DSP可降低89%功耗;运行Convolutional Recurrent Neural Network模型时,相较于HiFi5 DSP可降低88%功耗;运算Convolutional Deep Recurrent Neural Network模型时,相较于HiFi5 DSP可降低76%功耗。 最后,相同条件下在运算某CNN-Con2D算子模型时,GEN1 MMSCIM的实测AI算力可比HiFi5 DSP的实测算力高16.1倍。 综上所述,炬芯科技此次推出的最新一代基于MMSCIM端侧AI音频芯片,对于产业的影响深远,有望成为引领端侧AI技术的新潮流。 炬芯科技Actions Intelligence助力AI生态快速发展 从ChatGPT到Sora,文生文、文生图、文生视频、图生文、视频生文,各种不同的云端大模型不断刷新人们对AI的预期。然而,AI发展之路依然漫长,从云到端将会是一个新的发展趋势,AI的世界即将开启下半场。 以低延迟、个性服务和数据隐私保护等优势,端侧AI在IoT设备中扮演着越来越重要的角色,在制造、汽车、消费品等多个行业中展现更多可能性。基于SRAM的模数混合CIM技术路径,炬芯科技新产品的发布踏出了打造低功耗端侧 AI 算力的第一步,成功实现了在产品中整合 AI 加速引擎,推出CPU+ DSP + NPU 三核 AI 异构的端侧AI音频芯片。 最后,周正宇博士衷心希望可以通过“Actions Intelligence”战略让AI真正的随处可及。未来,炬芯科技将继续加大端侧设备的边缘算力研发投入,通过技术创新和产品迭代,实现算力和能效比进一步跃迁,提供高能效比、高集成度、高性能和高安全性的端侧 AIoT 芯片产品,推动 AI 技术在端侧设备上的融合应用,助力端侧AI生态健康、快速发展。
炬芯科技
炬芯科技 . 2024-11-08 3 1 1200

ExecuTorch 测试版上线,加速 Arm 平台边缘侧生成式 AI 发展
通过 Arm 计算平台与 ExecuTorch 框架的结合,使得更小、更优化的模型能够在边缘侧运行,加速边缘侧生成式 AI 的实现。 新的 Llama 量化模型适用于基于 Arm 平台的端侧和边缘侧 AI 应用,可减少内存占用,提高精度、性能和可移植性。 全球 2,000 万名 Arm 开发者能够更迅速地在数十亿台边缘侧设备上大规模开发和部署更多的智能 AI 应用。 Arm 正在与 Meta 公司的 PyTorch 团队携手合作,共同推进新的 ExecuTorch 测试版 (Beta) 上线,旨在为全球数十亿边缘侧设备和数百万开发者提供人工智能 (AI) 和机器学习 (ML) 功能,进而确保 AI 真正的潜力能被最广泛的设备和开发者所使用。 借助 ExecuTorch 和新的 Llama 量化模型,Arm 计算平台优化生成式 AI 性能 Arm 计算平台无处不在,为全球众多边缘侧设备提供支持,而 ExecuTorch 则是专为移动和边缘侧设备部署 AI 模型而设计的 PyTorch 原生部署框架。两者的紧密合作,使开发者能够赋能更小、更优化的模型,包括新的 Llama 3.2 1B 和 3B 量化模型。这些新模型可以减少内存占用、提高准确性、增强性能和提供可移植性,成为小型设备上的生成式 AI 应用的理想选择,如虚拟聊天机器人、文本摘要和 AI 助手。 开发者无需额外的修改或优化,便可将新的量化模型无缝集成到应用中,从而节省时间和资源。如此一来,他们能够迅速在广泛的 Arm 设备上大规模开发和部署更多的智能 AI 应用。 随着 Llama 3.2 大语言模型 (LLM) 新版本的发布,Arm 正在通过 ExecuTorch 框架优化 AI 性能,使得在 Arm 计算平台边缘设备运行的真实生成式 AI 工作负载能更为快速。在 ExecuTorch 测试版发布的首日起,开发者便能享有这些性能的提升。 集成 KleidiAI,加速端侧生成式 AI 的实现 在移动领域,Arm 与 ExecuTorch 的合作意味着众多生成式 AI 应用,如虚拟聊天机器人、文本生成和摘要、实时语音和虚拟助手等,完全能够在搭载 Arm CPU 的设备上以更高的性能运行。这一成果得益于 KleidiAI,它引入了针对 4 位量化优化的微内核,并通过 XNNPACK 集成到了 ExecuTorch 中,因此,在 Arm 计算平台上运行 4 位量化的 LLM 时,无缝加速 AI 工作负载的执行。例如,通过 KleidiAI 的集成,Llama 3.2 1B 量化模型预填充阶段的执行速度可以提高 20%,使得一些基于 Arm 架构的移动设备上的文本生成速度超过了每秒 400 个词元 (token)。这意味着,终端用户将从他们移动设备上获得更快速、响应更灵敏的 AI 体验。 为物联网的边缘侧 AI 应用加速实时处理能力 在物联网领域,ExecuTorch 将提高边缘侧 AI 应用的实时处理能力,包括智能家电、可穿戴设备以及自动零售系统等。这意味着物联网设备和应用能够以毫秒级的速度响应环境变化,这对保障安全性和功能可用性至关重要。 ExecuTorch 可在 Arm® Cortex®-A CPU 和 Ethos™-U NPU 上运行,以加速边缘侧 AI 应用的开发和部署。事实上,通过将 ExecuTorch 与 Arm Corstone™-320 参考平台(也可作为仿真固定虚拟平台 (FVP) 使用)、Arm Ethos-U85 NPU 驱动程序和编译器支持集成到一个软件包中,开发者可在平台上市前几个月就着手开发边缘侧 AI 应用。 更易获取、更快捷的边缘侧 AI 开发体验 ExecuTorch 有潜力成为全球最受欢迎的高效 AI 和 ML 开发框架之一。通过将应用最广泛的 Arm 计算平台与 ExecuTorch 相结合,Arm 正在通过新的量化模型加速 AI 的普及,让开发者能够更快地在更多设备上部署应用,并将更多生成式 AI 体验引入边缘侧。
ARM
Arm社区 . 2024-11-08 1000

艾迈斯欧司朗推出新版EVIYOS®多像素LED
2023年,艾迈斯欧司朗正式推出专为自适应远光灯(ADB)与投影式头灯设计的首代EVIYOS®多像素LED,为驾驶者夜间行车带来了全新体验。 EVIYOS®这一前沿技术已率先被应用于大众汽车的途锐与途观车型中,这些车型的头灯系统由马瑞利精心打造,每套系统均集成19,200个精密像素点,而EVIYOS®光源模块自身则可集成多达25,600个独立可控像素点。 基于EVIYOS®技术的智能头灯大大提高夜间道路可见度,而不会令对向行驶驾驶员感到眩目,显著优化了夜间驾驶体验。此外,EVIYOS® LED还具备在路面上投射符号与图像的功能,为车内与外界环境的通信(主要是在安全警示和传递其他信息上)开辟新的应用前景。 自这项创新技术面世以来,汽车行业对其的热情持续高涨,业界正积极探索多像素LED如何引领自适应远光灯(ADB)迈入照明新纪元。新一代ADB头灯为高级驾驶辅助系统(ADAS)增添了全新功能,同时也为汽车制造商在汽车前部的设计与创新造型方面提供了更多可能性。 初代 EVIYOS® HD 25 gen1 25,600个独立可控像素点; 专为汽车智能高分辨率前照灯设计。 新推出的EVIYOS® HD 25 gen2 彰显了艾迈斯欧司朗针对市场需求所做出的一些实用性优化。具体体现在: 亮度性能提升。初代EVIYOS® HD 25 gen1的典型亮度值为85 MNits。而在新一代EVIYOS® HD 25 gen2产品中,最低亮度已提高至85 MNits; 杂散光控制优化,极大简化头灯光学系统的设计与制造工艺; 供应链更具弹性。借助艾迈斯欧司朗的内部生产能力,确保配套ASIC(用于控制LED组件)的持续稳定供应与高质量。 EVIYOS®发展路线图为客户提供坚实可靠的时间规划保障 自EVIYOS®系列首款产品问世尚不足一年,EVIYOS® HD 25 gen2便迅速实现了产品功能的升级迭代,这充分体现了艾迈斯欧司朗坚定践行与汽车行业共享发展路线图的承诺。 EVIYOS® HD 25 gen2的发布严格遵循了这一路线图。公司还将陆续发布及推出新产品,包括已经面世的面向工业及商业照明的EVIYOS® Shape产品,以及未来专为中、低端车型设计的EVIYOS® LED版本。 在汽车领域,艾迈斯欧司朗还将宣布在新客户设计项目上的新成就:大众汽车率先采用了EVIYOS® LED的高分辨率投影技术,其他汽车制造商也紧随其后。因能增强夜间视野,提高道路安全性,同时赋予车辆外观设计更大的自由度,并支持打造如欢迎回家时的“光毯”照明效果及独特前部造型等个性化设计,这款头灯深受客户青睐。 EVIYOS® Shape适用于工业及商业照明应用 艾迈斯欧司朗已于近日宣布与小象光显联合发布全新μLED智能投影灯MLP3000。MLP3000由小象设计,采用“三高三化”(见下文)EVIYOS® Shape LED,可广泛应用于户外广告、文旅景观、商业展览等多元城市光影场景,助力打造极具交互感的视觉体验。 图:小象光显μLED智能投影灯效果展示 EVIYOS® Shape LED的“三高三化”特性: 高亮度:最高可达100 MNits; 高效率:按需点亮,节能可达80%; 高可靠:过温保护机制; 像素化:>25K个独立可控的像素点; 微型化:芯片尺寸<40μm; 智能化:与传感器或摄像头结合,甚至连接人工智能。 凭借着高亮、智能、低功耗、小体积等应用优势,EVIYOS® Shape LED必将在工业及商业照明领域掀起新一轮“像素化”风潮。 斩获Top 3EVIYOS®技术闪耀德国未来奖 德国联邦政府同样对EVIYOS® LED技术的创新给予了高度认可,并于2024年9月提名艾迈斯欧司朗参与角逐备受瞩目的德国未来奖——联邦总统技术与创新奖。经过多轮严格评审,EVIYOS®工程团队凭借卓越表现成功跻身该奖项的前三名。 本次提名中涉及的艾迈斯欧司朗工程师包括:新技术高级总监Norwin von Malm博士、系统解决方案工程团队负责人Stefan Groetsch,以及来自柏林弗劳恩霍夫可靠性与微集成研究所(IZM)的Hermann Oppermann博士。 此次提名正式肯定了EVIYOS® HD 25多像素产品所依托的LED技术领域的重大突破——但敬请期待:艾迈斯欧司朗正不断推进产品开发,EVIYOS®的故事仍在继续。
ams OSRAM
艾迈斯欧司朗 . 2024-11-08 2105

符合AQG324标准的车载充电用CoolMOS™ CFD7A 650V EasyPACK™模块
符合AQG324标准的EasyPACK™采用了最新的CoolMOS™ CFD7A 650V芯片和一个集成的直流缓冲器Snubber电路。完美的性价比组合,适用于车载充电器和电动汽车辅助系统应用。 产品型号: ■ F4-35MR07W1D7S8_B11/A 产品特点 高度可靠的压接式针脚 预涂热界面材料(可选) 可实现紧凑系统设计 可集成SMD 应用价值 引脚-PCB连接非常良好 更好的热性能 减少装配工作量 设计自由度更高 减少器件并联 竞争优势 可进行灵活的引脚设计 降低系统成本 可实现紧凑系统设计 应用领域 电动汽车车载充电OBC 框图
英飞凌
英飞凌工业半导体 . 2024-11-08 2 1435

元戎启行获1亿美元C1轮融资,布局全球量产和Robotaxi运营
2024年11月5日,元戎启行宣布完成1亿美元C1轮战略融资,由国内头部主机厂独家投资。本轮融资将用于夯实国内量产项目,拓展海外业务,同时为探索Robotaxi商业化运营和布局VLA模型等前沿技术提供资金支撑。 元戎启行CEO周光表示:“本轮融资的完成,代表我们的技术实力和工程化能力已经得到汽车产业链的深度认可。下一步,元戎启行将结合投资方及合作伙伴的资源优势,通过智能驾驶赋予AI类人的思考能力、判断能力,最终实现通用人工智能。我相信通用人工智能时代,AI会成为基础设施,也坚信元戎启行会是AI 3.0时代的主要参与者。” 元戎启行布局全球量产和Robotaxi运营 元戎启行核心研发团队是业内最早一批从事人工智能研发及落地的团队。从率先推出“无图”方案,到推出端到端智能驾驶模型DeepRoute IO,元戎启行始终走在AI探索的最前沿。下一阶段,元戎启行将夯实算力基础,补充高精尖核心人才,加速布局前沿人工智能技术。 据悉,作为英伟达的资深合作伙伴,元戎启行是国内第一批获得Thor芯片的企业,元戎启行将基于该芯片进行VLA模型(Vision-Language-Action Model,视觉-语言-动作模型)的研发,该模型预计将于2025年正式推出。通过VLA模型,智能驾驶系统将拥有更高阶的思考能力,能够理解交通场景中复杂的交互事件、隐藏的语义信息并进行逻辑推理。 VLA模型可解释、更类人,全程可求导 目前,元戎启行已成功将端到端模型部署上车,并与多家主流车企达成合作,共同推进十余款车型的量产。预计今年年底,将有三款搭载元戎启行智能驾驶系统的车型推向消费者市场。同时,元戎启行将利用其在国内的量产经验赋能海外车企业务发展。 此外,元戎启行正在探索新的商业化路线——基于端到端模型,用量产车实现Robotaxi的规模化运营。与传统的Robotaxi不同,元戎启行的Robotaxi不受运营区域限制,在时间成本和经济成本上更具优势,有助于加快Robotaxi的落地进程。 随着智能驾驶汽车的量产上路和Robotaxi的规模化运营,元戎启行的智能驾驶系统将更好地理解物理世界的客观规律,拥有更高阶的思考能力,并进化成物理世界的通用人工智能,从而赋能千行百业。 作为国际领先的人工智能企业,元戎启行致力于打造“物理世界的通用人工智能”,以创新技术引领智能驾驶行业变革。随着智能驾驶汽车量产上路获取大量物理世界的脱敏数据,元戎启行将打造具备人类高阶智慧的“AI大脑”,赋能千行百业,为人类社会发展注入全新生产力。 元戎启行由CEO周光博士带领团队于2019年创立,总部位于深圳,在全球多地有业务落地。元戎启行始终坚持自主创新,成功推出最新一代不依赖高精度地图、应用端到端模型的智能驾驶平台DeepRoute IO,并与多家车企建立了量产合作关系,多款合作车型正陆续投入消费者市场。元戎启行相信智能驾驶技术将为通用人工智能的实现带来全新契机,开启人类智能发展的新篇章。
Robotaxi
元戎启行DeepRoute . 2024-11-08 940

NearStack 100欧姆连接器和电缆组件
NearStack 100欧姆连接器及电缆组件专为空间受限的电信与数据中心设计,旨在实现速率提升。该组件提供跳线式和I/O BiPass连接,是一种布局紧凑、插配高度低的Near-ASIC布线方案,支持高达56 Gbps PAM-4速率。 ▲NearStack100欧姆连接器 特色优势 减少高速数据应用场合的插入损耗 差分线对(DP)之间采用双地结构和无需PCB的线对线直连,提高了56 Gbps PAM-4的电气性能。 优化印刷电路板布局,提高有限空间的使用效率 相邻信号针0.60毫米的间距,相邻差分线对2.40毫米的间距。每平方英寸可以容纳30至50个差分线对,这种设计能在狭小空间内提供高数据速率传输,非常适合100欧姆的网络和top-of-rack(TOR)应用场合。 能够以最少的模具投资来增加差分线对数量 所有片式触点被安置于若干托架内,可从8个差分线对轻松扩展到16个差分线对。 为密集排列的设备提供安全连接 内置的双搭扣结构提供高达 25牛的保持力,而带有拉带的强制锁定结构能将保持力增加到大约 50牛。 与印刷电路板牢固连接 镀锡不锈钢焊脚通过浸膏处理,确保插头与印刷电路板的稳固连接。 应用场合 服务器和储存器:TOR交换机、核心路由器、数据中心交换机 电信:信号塔、远程无线电单元 组网:以太网应用、线缆桥架 规格参数 参考信息 包装: 卷带包装 设计计量单位:毫米 是否符合RoHS标准:是 是否无卤素:是 电气参数 电压(最大值):29.9伏RMS 电流(最大值):每对额定电流 0.25安培 阻抗:100 欧姆 接触电阻(最大值):30 毫欧姆 绝缘耐压:300伏RMS 绝缘电阻:10 兆欧 信号连续性:无大于 1 微秒的中断 机械参数 间距:0.60毫米(表面贴装接点之间)、 2.40毫米(差分线对之间) 插配高度:8.70毫米 电路板上占用面积:8.40 x 17.50毫米 出线角度:45 度角 锁定方式:双侧搭扣 引脚数:32 或 64 个引脚(8 或 16 个 差分线对) 对配力(最大值):2牛 拔脱力:25牛 可插拔次数(最小值):100 次 物理参数 塑壳:LCP UL 94 V-0,黑色 接点材料:铜 电镀: 接点部位 — 0.76微米选择性镀金 表面贴装焊尾部位 — 0.05微米选择性镀金, 底层整体镀镍1.27微米 工作温度:-40 至 +85摄氏度
molex
Molex莫仕连接器 . 2024-11-08 1110

电机产品线上新 | 极海推出GHD3440Rx进阶升级版电机专用栅极驱动器
低压差线性稳压器(LDO)的主要作用是将输入电压稳定到一个恒定输出电压,为电机控制系统提供稳定的电源,确保电机控制信号的精确性和可靠性,在系统设计中可与栅极驱动器集成,确保栅极驱动器高频率切换的稳定性。 极海针对用户系统设计的多样化需求,推出了新款电机专用栅极驱动器GHD3440Rx,GHD3440Rx作为GHD3440的升级版本,内置3.3V/5V LDO,可提供GHD3440R3和GHD3440R5两种型号,有助于节省板上空间占用,降低客户硬件成本,提高系统可靠性。 GHD3440Rx产品特点 集成化设计:简化电路、压缩空间,为电机系统设计提供更高灵活度 增强稳定性:抗干扰能力强,降低系统开关损耗、减少系统发热量 安全再升级:欠压保护、直通防止、死区保护、过温保护等 高集成 | 更灵活、更稳定 GHD3440Rx电机专用栅极驱动器,提升了面向低压应用场景的驱动能力,集成的LDO电路可从DC-DC转换电路为MCU提供稳定的低噪声电源,负载能力60mA@15V,输出误差在2%以内,确保在负载突变时保持最小电压波动,增强抗干扰性能、提升开关效率;高度集成的SSOP24封装可有效减少电路板空间、降低硬件成本,为用户提供更多分立式电机系统设计解决方案。 高性能 | 提升电机运行效率 支持5V~20V输入电压范围,3.3V/5V逻辑输入兼容,悬浮偏移电压+200V,适用于各种电池供电的直流无刷电机应用方案;峰值输出电流0.9A@15V、3.3nF负载上升时间90ns,峰值输入电流1.1A@15V、3.3nF负载下降时间60ns,有效提高功率器件的开关速度,降低开关损耗。 高安全 | 提供多重保护功能 内置VCC/VBS欠压(UVLO)保护功能,防止功率管在过低的电压下工作;内置基于输入信号的直通防止和500ns典型死区时间保护电路,防止被驱动的高低侧MOSFET直通,有效保护功率器件;内嵌输入、输出下拉电阻,具备高DV/DT噪声抑制能力,提供稳定驱动能力;过温保护阈值 151℃/131℃,确保在负载变化时系统能在安全温度范围内正常工作。 GHD3440Rx电机专用栅极驱动器的推出,可满足电机控制应用对精简电路、提高系统性能的需求。极海还将陆续推出满足电机市场应用需求的,具备先进性、可靠性及高性价比的芯片及解决方案,并提供完善的工具链、多场景DEMO、以及快速周到的技术支持服务,为客户提供一站式开发体验,满足其深度开发需求。
极海
Geehy极海半导体 . 2024-11-07 1 1470
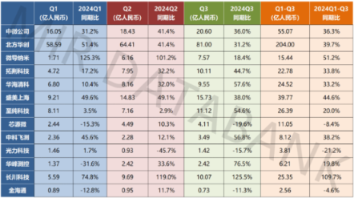
2024年前三季度,中国半导体设备及材料厂商业绩能否再创佳绩?
近日,半导体设备及材料公司陆续公布三季报,为方便更清晰地对比,MIR睿工业整理了主要厂商2024年前三季度营业总收入、扣除非经常性损益后的净利润一览表(排名不分先后),供大家更清晰的参考。 *以下数据表格中标注“不适用”,是由于公司没有发生非经常性损益事项、财报编制规则的要求或者会计与税法差异导致。 01 半导体设备 2024年中国主要半导体设备厂商营收数据统计-分季度 (数据来源:MIR 睿工业根据公开资料整理) 2024年中国主要半导体设备厂商扣除非经常性损益后的净利润统计-分季度 (数据来源:MIR 睿工业根据公开资料整理) 2024年前三季度中国主要半导体设备厂商普遍呈现增长态势,个别厂商因经营不善出现下滑;第三季度普遍还是延续了上半年高速增长态势。扣非净利润方面,长川科技前三季度同比增超42倍,增速位居第一,北方华创和华海清科的扣非净利润再度刷新了单季度历史新高,但仍有不少厂商的扣非净利润情况并不理想。 长川科技表现亮眼,前三季度共实现营收约25.35亿元,同比增长109.7%。长川科技表示,业绩高速增长主要是因市场回暖,公司销售规模扩大。 盛美上海在前三季度实现营收约39.77亿元,同比增长44.6%。根据财报显示,业绩快速增长是由于中国半导体行业设备需求持续旺盛,公司在新客户拓展和新市场开发方面取得了显著成效。盛美上海也在积极推进现有产品的改进,并不断开发新工艺和新产品。在前三季度,盛美上海的研发投入也达到了6.12亿元,同比增长超过了四成。 中微公司在前三季度营收为55.07亿元,同比增长约36.3%。根据财报显示,主要系公司的等离子体刻蚀设备在国内外持续获得更多客户的认可,针对先进逻辑和存储器件制造中关键刻蚀工艺的高端产品新增付运量显著提升,先进逻辑器件中段关键刻蚀工艺和先进存储器件超高深宽比刻蚀工艺实现量产。中微公司在披露2024年三季报的同时透露,市场对于公司开发的多种新设备的需求正在急剧增长。为了尽快补齐短板,实现赶超,中微公司在2024年显著加大了研发力度。数据显示,2024年前三季度,中微公司的研发支出高达15.44亿元,同比增长约95.99%,研发支出占其营收的比例也达到了约28.03%。 02 半导体材料 2024年中国主要半导体材料厂商营收数据统计-分季度 (数据来源:MIR 睿工业根据公开资料整理) 2024年中国主要半导体材料厂商扣除非经常性损益后的净利润统计-分季度 (数据来源:MIR 睿工业根据公开资料整理) 从数据统计来看,半导体材料公司三季度业绩整体呈现分化态势,部分公司实现了高速增长,但也有不少公司面临负增长的压力。 天岳先进2024年前三季度营收为12.81亿元,同比增长55.34%。根据财报显示,业绩增长得益于公司在导电型碳化硅衬底业务方面的快速发展,与国际一线大厂的合作和车规级产品优势,推动天岳先进在2024年前三季度的收入规模已超越2023年全年,扣非净利润扭亏为盈。 雅克科技2024年前三季度累计总营收达到49.99亿元,同比上升41.15%。根据财报显示,业绩增长主要原因包括LNG板材和电子材料板块需求的增加、新产能的释放以及前驱体需求的旺盛。 沪硅产业2024年前三季度实现营收24.79亿元,同比增长3.70%。对于业绩的波动,沪硅产业表示,主要系几方面因素影响:一是公司当前集成电路用300mm硅片正处于高投入阶段,二期及三期项目正在快速建设中,这在一定程度上增加了运营成本;二是市场复苏效应传导到上游硅片仍需时间,对公司产品的价格造成了一定压力;三是公司产品结构进一步升级,研发投入增加,导致短期业绩有所波动。沪硅产业2024年前三季度投入研发的金额达到2.08亿元,同比增长18.74%,研发投入占营收比为8.40%。 从数据统计来看,中国半导体设备及材料厂商间的营收和扣非净利润差异明显。面对行业挑战,国内企业正通过加大研发投入和加速新品量产来增强竞争力。未来两年内,国产替代政策的支持将为半导体设备及材料板块提供强有力的支撑和催化作用,也将进一步促进中国半导体产业的自主可控和转型升级。
半导体设备
MIR睿工业 . 2024-11-07 3885

下一代汽车微控制器如何重塑未来汽车?意法半导体总裁揭秘最新战略
电动化和数字化正在给汽车行业带来深刻巨变。尽管最近一些汽车厂商缩减了汽车电动化计划,但是我们仍然认为,经济实惠的混合动力和电动汽车未来将主导汽车市场,未来汽车将是软件定义的汽车,采用以太网作为主要的车载总线协议。无线下载(OTA)软件更新确保汽车功能得到不断改善,无缝集成新功能,因此,OTA将是决定终端用户的汽车体验好坏的关键。随着软件更新功能到来,市场对存储空间和读写性能的需求不断提高,因为只有充足的存储空间和优异的读写性能才能保证在整个汽车生命周期内不停机地扩展功能。 这个未来功能在一些造车新势力的车型中已经变为现实。与此同时,传统车企正在逐步采用这些创新技术,通过渐进式的演变过程逐步转变汽车架构。尽管各地区的汽车制造商面临不同的挑战,但他们有共同的主题:提高竞争力、实现可持续发展目标、投资优越技术,以及调整商业模式。这些要求给汽车制造商、一级供应商和其他供应商带来了巨大的挑战,迫使他们提高生产效率,解决设计复杂性问题,缩短其软件定义车辆(SDV)的开发时间。 ST的使命是帮助一级供应商和汽车OEM厂商加快转型。我们提供完整的产品组合,能够满足从本地执行器和智能传感器到高性能实时处理的所有需求,并实现跨应用领域的功能整合,将多个不同应用领域的功能整合在一起。 作为推动这一转型战略的核心,我们正在按照ST的垂直整合制造(IDM)模式,沿着两大支柱制定汽车微控制器开发战略。目前,我们正在构建业界首个基于Arm®的产品组合,涵盖从低端到高端解决方案的汽车MCU的全部应用范围: Stellar产品家族:一个可扩展的基于ARM的硬件架构,支持多个ASIL ECU实时虚拟化,具有丰富的IO端口和外设,并提供独特的OTA价值主张。这个架构采用我们内部开发的嵌入式非易失性存储器技术(eNVM)和28nm FD-SOI技术。 这是业内在eFlash之后推出的首个嵌入式非易失性存储器技术,是市场上最成熟、最小的汽车级存储单元解决方案的代表。Stellar产品家族适合汽车电动化应用,包括X-in-1高集成度车辆电机控制计算机、新型车辆架构,以及用于ADAS、区域制和车身集成等安全关键子系统的安全MCU。 STM32A:是STM32产品家族中的全新系列,以STM32为基础,采用ST的eNVM制造技术。STM32A系列主要用于汽车网络边缘执行器,例如,车身控制和智能传感器管理,并将支持ASIL B级汽车安全标准。 扩展后的ST基于Arm的汽车微控制器(MCU)产品组合将具备下一代汽车电气/电子(E/E)架构系统所要求的全部功能。通过不断增长的生态系统合作伙伴,两个平台都增强了其硬件价值,能够为客户提供更简单、更快速和更高效的开发。 我们已经成功推出了Stellar P和G两个系列,这两个系列已经通过了客户的认证测试。而且,我们很快将迎来一个重要的里程碑,新产品将开始进入量产阶段。Stellar产品在亚洲和欧洲客户中正获得越来越多的关注。例如,比亚迪正在大幅改进下一代汽车电气化系统架构,将多个电子单元集成到一个精简高能效的设备中。 未来,我们将创建一个统一的MCU平台开发战略,简化产品设计,提高可扩展性,降低开发复杂性,同时确保安全性和可靠性达到更高水平,并将提供更出色的性能和能效,帮助车企降低整体制造成本。最终,该战略将整合ST的工业和汽车两种微控制器平台的软硬件精华,满足汽车行业在边缘AI和安全等领域日益增长的需求。 边缘AI技术是我们看到的一个现有工业技术应用到未来汽车行业的例子。神经加速器开发工具让开发人员能够在其应用中轻松实现AI,不受他们的数据学专业知识水平的限制,将来,神经加速器技术及其相关工具将改进汽车系统。安全性是我们看到的另一个工业与汽车技术融合带来显著好处的应用领域。 总之,意法半导体致力于帮助汽车行业应对电气化和数字化的挑战,不仅提供现阶段所需的解决方案,未来还提供更强大的统一的MCU平台开发战略,降低设计复杂性,确保汽车的安全性和可靠性,并提供更高的性能和能效,最终,将支持下一代车辆架构和软件定义汽车的开发。 与我们一起踏上令人期待的未来汽车转型征程。 欣旺达创始人王明旺表示,“作为全球锂离子电池的龙头企业,欣旺达为全球汽车供应商提供稳定可靠的汽车电子系统解决方案。我们与意法半导体的新合作专注于利用ST的先进Stellar微控制器和专有生产工艺开发解决方案,主要包括电池管理系统以及VDC/区域和车身控制功能。我们共同的目标是提供智能解决方案,改进中国及全球的下一代新能源汽车。” “随着驾驶体验在AI和软件定义车辆时代的不断演变,提升汽车功能性安全、灵活性和实时性能至关重要,”Arm汽车业务线高级副总裁兼总经理Dipti Vachani表示,“基于Arm构建的Stellar微控制器系列利用Arm计算平台的先进安全性和实时功能,以及广泛的Arm软件生态系统,让汽车制造商能够在遵守严格安全法规的同时,实现创新功能,在汽车领域保持领先地位。” “通往软件定义车辆的道路将以动力系统的电气化为基础,从而增强数字化、车辆连接性和驾驶自动化能力。这是通过区域和集中控制器提供必要的计算能力来实现的,”TechInsights汽车市场分析执行董事Asif Anwar表示,“意法半导体作为排名前列的汽车MCU供应商,利用其Stellar系列满足SDV需求和X-in-1集成的增长趋势,为OEM提供重新构想车辆架构的路径,提供无缝融合多种功能的解决方案。凭借可扩展、安全和高性能的MCU,优化的电源效率和内部开发,ST正在赋能汽车行业创新未来。”
意法半导体
意法半导体中国 . 2024-11-07 1465
- 1
- 45
- 46
- 47
- 48
- 49
- 500